We are at the Day #3 of my 30-days OpenBOM blogging journey. Check the first article – OpenBOM in 30 days. Today, we will speak about OpenBOM architecture.
Why PLM Architecture Matters – Agility, Scalability, Security
When people think about PLM, they often focus on features: version control, BOMs, change orders. Yet, architecture is the invisible foundation that determines how easily product data can be organized, how fast teams can collaborate, and how safely information is stored.
A modern PLM must do more than manage engineering files. It has to scale globally, adapt quickly to changing supply-chain needs, onboard new users in minutes, and keep data secure across many companies and partners.
Cost economics also depends on architecture: a well-designed multi-tenant platform can serve thousands of small and mid-size companies, individual contributors, consultants, and developers at a fraction of the cost of legacy enterprise stacks.
Traditional PLM systems were invented for large defense, aerospace, and automotive programs decades ago. They were powerful but built long before today’s global web architectures, cloud infrastructure, NoSQL databases, graph data models, or AI-driven analytics.
These older designs are still tied to heavy on-premise deployments, long implementations, and siloed upgrades.
OpenBOM was designed in the cloud era. A new account can be registered and ready to use—complete with CAD integrations and a flexible data model—in under a minute. That difference in onboarding speed alone reflects how architecture shapes usability.
Traditional vs Modern PLM Stack
Legacy PLM stacks were typically single-tenant, SQL-centric, and monolithic.
Each customer ran its own isolated copy of the application and database, requiring separate infrastructure, unique customizations, and long upgrade cycles. These silos slowed collaboration and innovation.
Modern PLM platforms like OpenBOM are multi-tenant, polyglot-persistent, graph-based, AI-enabled, and cloud-native.
A multi-tenant platform lets all customers share the same secure infrastructure with logically isolated data, so updates are delivered instantly and consistently.
Polyglot persistence means using the right database for the right job—graph for relationships, NoSQL for flexible catalogs, search engines for indexing—allowing speed and flexibility without sacrificing integrity.
This approach makes it easier to connect data across teams, automate workflows, and scale globally without the cost burden of duplicate stacks.
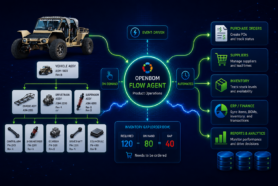
Core Components of OpenBOM
At the heart of OpenBOM is a multi-tenant micro-services architecture running on leading cloud IaaS providers (AWS ECS today, with Azure and GCP supported for enterprise deployments).
This design offers elastic scalability and global availability.
OpenBOM uses polyglot persistence:
- Neo4j Graph Database for storing complex product relationships.
- MongoDB/NoSQL for flexible data schemas like catalogs and attributes.
- Elastic-style search services for quick retrieval and indexing.
We’ve also made the platform AI-ready at the core data level: supporting modern data-management tools such as embeddings to power semantic search, classification, and other AI-driven insights.
Developers and integration partners work through Open REST and GraphQL APIs, with the MCP Server (Model Context Protocol) providing structured product context for both application integrations and emerging AI/agentic workflows.
This technology stack ensures that OpenBOM can grow with customers—whether they have 5 users or 5,000.
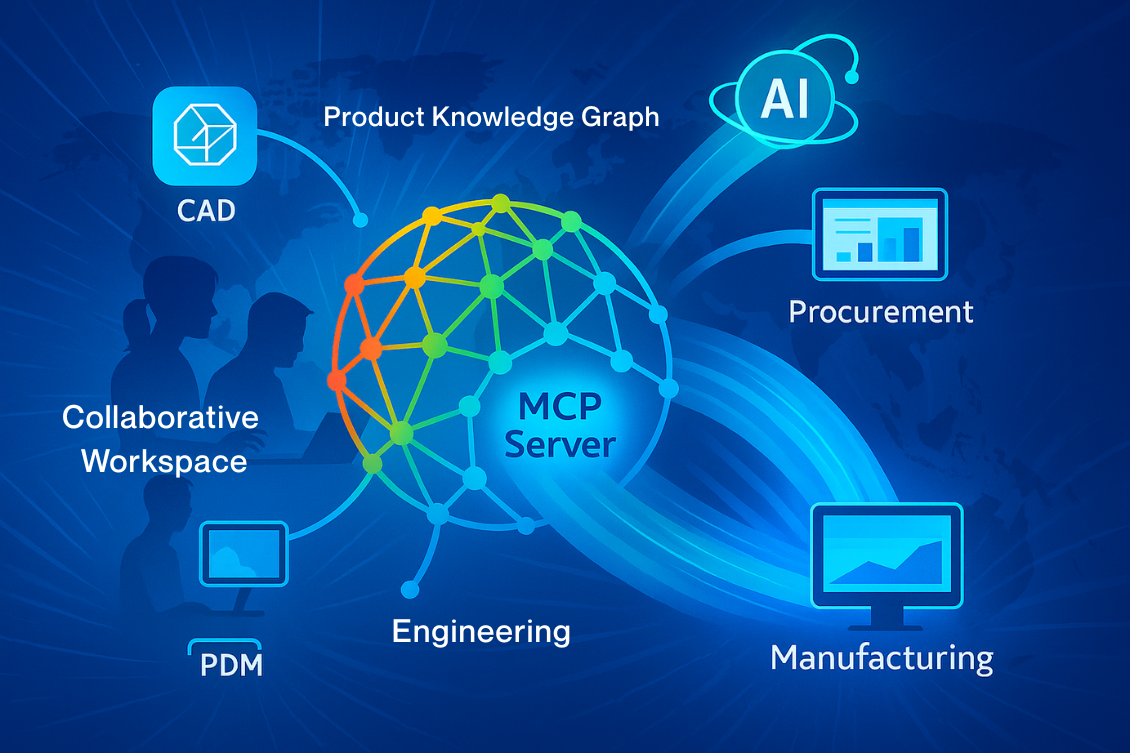
OpenBOM Architecture Diagram
A visual diagram helps bring these components together:
- Multi-tenant Cloud Infrastructure (AWS ECS, containers, scaling services).
- Data Services (Neo4j Graph for product memory, MongoDB for catalogs, search index, file storage).
- Integrations, API & MCP Layer: REST / GraphQL APIs and MCP Server exposing product context to apps and agents.
- Global product graph for intelligence and analytics. Including AI & Product Memory Overlay: AI agents operating on structured graph-based product memory to support decision-making, validation, and insights.
- Collaborative Workspace (Google-Sheets-like data editor)
- Integrations including CAD add-ins, ERP and other integrations
- Application services focusing on Design (PDM), xBOM, Inventory and procurement.
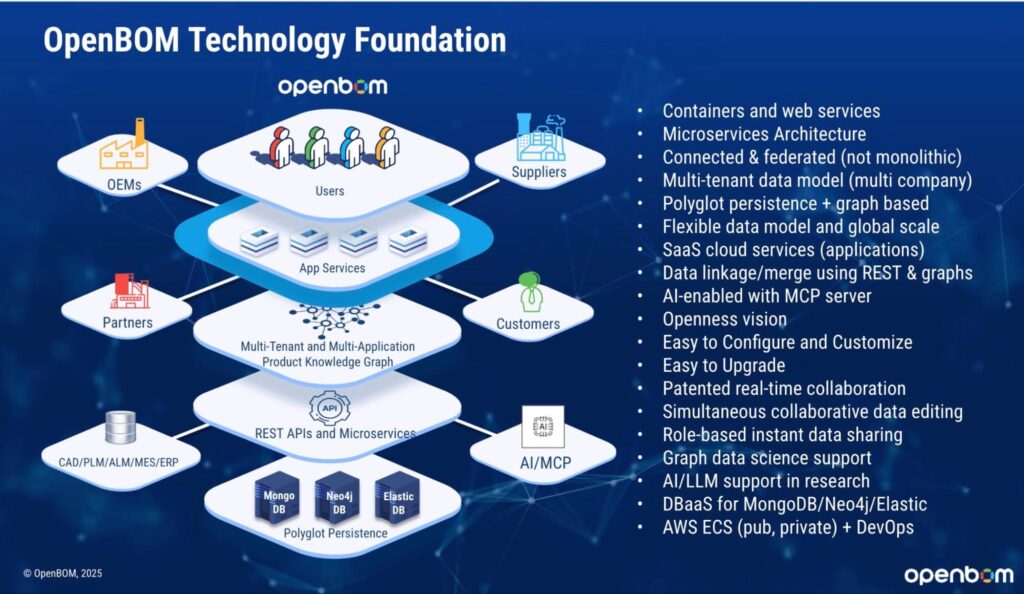
This diagram illustrates how the architecture is layered and shows the flow of data from the infrastructure to collaboration tools, emphasizing why OpenBOM is both robust and future-ready.
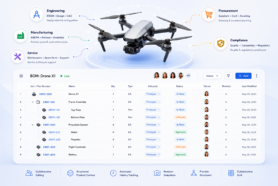
Collaboration Layer – Familiar but Powerful
Above this data foundation is OpenBOM’s “Collaborative Workspace”—a layer purpose-built for simultaneous, secure, real-time data editing.
Its Google-Sheets-like interface feels approachable to engineers and buyers accustomed to spreadsheets but provides full change-tracking, revision control, and granular access permissions behind the scenes.
Because the collaboration layer is tied directly to the multi-tenant backend, every edit is reflected instantly across teams and locations, avoiding the need to sync or email files.
It’s the blend of familiar user experience with enterprise-grade architecture that makes adoption easier for small teams while meeting the security and traceability expectations of larger enterprises.
Future-Proofing – Product Memory and AI
The same graph-based data model that powers product data today also lays the groundwork for the concept of product memory—a persistent knowledge layer that links designs, revisions, suppliers, cost, compliance, and lifecycle events.
Through the MCP Server, this product memory becomes accessible to AI Agents that can reason about product structures, validate BOM consistency, suggest alternates or substitutes, flag missing attributes, and help teams explore cost or supply-chain trade-offs—directly within their existing workflows.
This isn’t just solving today’s CAD-to-BOM problems. It’s preparing manufacturers for the next generation of connected, intelligent, agent-assisted workflows.
Conclusion:
OpenBOM’s architecture was purpose-built to give manufacturing companies the scalability of the cloud, the flexibility of graph-based product data, the affordability of multi-tenant economics, and the usability of collaborative spreadsheets—ready for the age of AI.
By understanding this foundation, you’ll see why OpenBOM can onboard a team in minutes, connect seamlessly to CAD and ERP tools, and evolve as your processes mature.
In Day 4 of this series, we’ll explore the xBOM service in depth—how OpenBOM models product structures for engineering, manufacturing, and service views without duplicating data.
REGISTER FOR FREE to check how OpenBOM can help you.
Best, Oleg
Join our newsletter to receive a weekly portion of news, articles, and tips about OpenBOM and our community.