Why the PLM data problem is really a workflow problem and why review, validation, and context must become the new center of product development.
A mechanical engineer finishes the design on Thursday. He releases the drawings, exports the BOM to Excel, packages the STEP files, and sends everything to procurement. Procurement imports the BOM into the finance system. The data looks clean. The columns are right, the part numbers match, the quantities add up.
Two days later someone discovers the problem.
The electrical team was working in a different system. Their BOM export had a slightly different structure – different column names, a different part numbering convention, one field mapped differently. Nobody caught it because both files looked like BOMs. Both had the right format. Both imported without errors.
But the consolidated bill of materials that landed in the finance system was wrong. Components were missing. Some quantities were off. One assembly appeared twice under different identifiers. The finance system accepted all of it without complaint because the data was structurally valid. It was just factually incorrect.
The mechanical engineer didn’t make a mistake. The electrical team didn’t make a mistake. Procurement followed the process. The finance system did exactly what it was told.
The workflow made the mistake. And nobody knew until two days later, when someone tried to use the output.
Why PLM Data Problems Keep Happening
The root cause of most PLM data problems is not bad data. It is a workflow designed for a world that no longer exists.
The pipeline model – CAD to BOM to Excel to ERP – was built on a reasonable assumption. Engineering creates product data, releases it, and hands it downstream. In a world where one discipline, one system, and one file format dominated the process, this worked well enough. Traditional PLM was designed around exactly that model: control the CAD file, manage the BOM, release the item, approve the change, send the data downstream.
Modern product development broke all three assumptions. Mechanical, electrical, software, and systems engineering teams now work in parallel, each with their own tools, their own export formats, and their own timelines. A product BOM is no longer the output of one team working in one system. It is the result of multiple disciplines, multiple data sources, and multiple handoffs – all of which need to be consolidated into something coherent before it reaches manufacturing, procurement, or finance.
The pipeline was never redesigned for that reality. So companies adapted by adding more steps: more spreadsheets, more email threads, more manual reconciliation, more people checking other people’s exports before import. The process got longer. The gaps between systems got wider. And somewhere in those gaps, context gets lost.
The scenario that opened this article is not an edge case. It happens in companies of every size, across every industry that builds physical products. The specific failure mode changes. The underlying cause does not.
The Question Traditional PLM Doesn’t Ask Early Enough
What if the outcome is wrong?
Traditional PLM is well-equipped to answer questions about what was released, who approved it, and when it changed. It is not designed to catch errors while product data is still forming, moving, and being consolidated across teams.
By the time a BOM error surfaces in the finance system or on the manufacturing floor, it has already traveled through several handoffs. The mechanical BOM was exported. The electrical BOM was exported. Both were sent to procurement. Both were imported. The finance system processed the result. Each of those steps looked correct in isolation. The error wasn’t visible at any single step – it lived in the gap between them.
This is the structural weakness of pipeline-style PLM. Data moves forward, but context stays behind. The mechanical engineer knows which revision he exported. The electrical team knows their file was current. Procurement knows they followed the instructions they were given. But nobody owns the space between those steps – the consolidation, the conflict check, the validation that the combined output actually reflects what both teams intended.
Traditional PLM treats that space as a handoff. Modern product development needs it to be a workflow.
The cost of discovering BOM errors downstream is not only the rework. It is the investigation. Someone has to reconstruct what happened, trace which file came from where, figure out when the divergence occurred, and determine who needs to be involved in the fix. That investigation consumes time that should have been spent building the product. And it happens repeatedly, because the workflow that produced the error is still in place.
Two PLM Workflows Compared: Pipeline vs. Product Memory
The clearest way to see what needs to change is to run the same scenario through two different workflows.
A product team is preparing for a manufacturing handoff. The mechanical team has been working in SOLIDWORKS. The electrical team has been working in a separate ECAD system. Both teams need to contribute their BOM data to a consolidated product structure that will flow to ERP and procurement. The deadline is Friday.
The traditional CAD-BOM-ERP pipeline
Each team exports their BOM to Excel. The files land in a shared folder or arrive by email. Someone – usually a product manager or a senior engineer – opens both files and begins manually reconciling them. Column names don’t match. One team uses manufacturer part numbers as the primary identifier; the other uses internal part numbers. One file has quantities per assembly; the other has total quantities. Some components appear in both BOMs because they are shared across disciplines, but they are listed under different descriptions.
The reconciliation takes most of a day. A consolidated Excel file is produced and sent to procurement. Procurement imports it into the finance system. The import runs without errors. On Friday the handoff is declared complete.
Two days later the problem surfaces. A component that the electrical team added in their final revision wasn’t in the export used for reconciliation. The Excel file the product manager worked from was a version behind. The finance system has the wrong data. Procurement needs to be notified. The supplier needs to be contacted. Someone needs to figure out whether anything was already ordered against the wrong BOM.
The Product Memory workflow with OpenBOM
Both teams connect their source systems to OpenBOM. The mechanical team works in their SOLIDWORKS environment; the electrical team works in their ECAD environment. As each team progresses, their BOM data is captured into a shared OpenBOM workspace – not as static exports, but as a living product structure that reflects current state.
When the mechanical and electrical BOMs are brought together in OpenBOM, the platform surfaces the consolidation immediately. Shared components are identified across both structures. Conflicts – different descriptions for the same part number, quantity mismatches, components present in one BOM but missing from the other – are flagged before any data flows downstream. The product manager doesn’t need to reconcile two Excel files manually. The system has already mapped both structures and shown exactly where they agree and where they don’t.
The team reviews the conflicts in OpenBOM. The electrical team clarifies the late-added component. The mechanical team confirms the shared parts. Decisions are made and recorded in context – not in a separate email thread, not in someone’s memory, but attached to the product structure where they belong. Once the review is complete and the consolidated BOM is validated, it flows to ERP and procurement with full traceability: every component linked to its source, every decision captured, every revision visible.
On Friday the handoff is complete. And it is actually correct.
The difference between these two workflows is not the quality of the engineers or the care of the product manager. It is where validation happens. In the traditional pipeline, validation happens downstream – after the data has already traveled, been imported, and been acted on. In the Product Memory workflow, validation happens before the data moves, while the context is still present and the people who made the decisions are still available.
What Is Product Memory and Why Does It Matter for PLM?
Product Memory is the contextual layer that makes the new workflow possible.
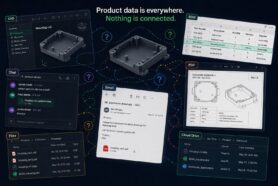
It is not a database. It is not another promise of a single source of truth. Product Memory is the layer that captures product information from multiple sources – CAD systems, ECAD tools, spreadsheets, supplier data, ERP records – and preserves the relationships, versions, decisions, and assumptions that static BOM exports leave behind.
When two BOM exports arrive from two different engineering teams, Product Memory doesn’t just store both files. It maps them against each other, surfaces the conflicts, and creates a reviewable product structure that carries the reasoning behind every component and every decision. When that structure flows downstream to ERP or procurement, it doesn’t arrive as a spreadsheet that looks correct. It arrives as a validated, traceable product record that actually is correct.
This distinction matters most not at the moment of import, but months later – when someone needs to understand why a component was changed, which team owned a particular assembly, or what assumption drove a sourcing decision. That context is what traditional pipelines lose at every handoff. Product Memory is designed to preserve it across the full product lifecycle.
OpenBOM is built around this principle. The platform captures multi-source BOM data, maintains context across engineering disciplines, supports collaborative review and conflict resolution, and enables validated data to flow downstream with full traceability – replacing the Excel reconciliation loop with a structured, auditable workflow.
Review and Flow: The New Center of PLM
The central question for modern PLM is not where master data lives. It is how product information moves from uncertainty to decision to execution – and whether it carries its context along the way.
Traditional PLM was built around control: vault the CAD file, release the item, approve the change order, send the BOM downstream. This discipline remains essential. But control applied only to formal records misses most of where product decisions actually happen. They happen during review, during BOM consolidation, during supplier negotiation, during manufacturing planning – in the messy middle of product development where nothing is officially released yet but everything consequential is being decided.
If PLM doesn’t support that middle layer, companies fall back to Excel, email, and manual reconciliation. Not because they want to, but because the alternative – waiting for everything to be formally released before it can be reviewed – is too slow for how modern products are built.
Review and flow need to become the new center of product development infrastructure.

Review means the ability to compare, validate, and interrogate product information before it moves – while the people who understand it are still available and the context is still intact. Flow means the ability to move that information across teams, systems, and organizations without losing the traceability that makes it trustworthy.
This is the direction PLM needs to move. Not away from control and traceability, but forward from them – into a model that supports the full lifecycle of product information, from the moment it is first captured to the moment it reaches manufacturing, procurement, and beyond.
Stop Cleaning Data That Broken Workflows Keep Dirtying
Companies invest heavily in PLM data quality. They normalize item masters, reconcile BOMs, migrate to new ERP systems, and build integrations between engineering and manufacturing systems. These investments are necessary. They are not sufficient.
If the workflow continues to lose context at every handoff, the data will become wrong again. The finance system will import another incorrect consolidated BOM. The manufacturing floor will work from another outdated product structure. Another engineer will spend two days investigating a problem that a better workflow would have caught in two minutes.
The product data problem is painful not because companies don’t care about data quality. It is painful because they keep trying to fix it as a data problem, when the root cause is a workflow problem.
Rethinking that workflow – from a release pipeline that pushes data downstream to a contextual system that captures, consolidates, validates, and flows product information with its meaning intact – is the shift that changes the outcome.
The scenario at the beginning of this article doesn’t have to end the way it did. With the right workflow, the conflict between the mechanical and electrical BOMs is visible before Friday, not discovered on Sunday. The finance system receives correct data. Procurement acts on it with confidence. And the engineer who built the design doesn’t spend Monday morning on a call explaining what went wrong.
That is not a vision of some future PLM system. It is what a workflow built around Product Memory makes possible today.
Register for free to check how OpenBOM can help you.
Best, Oleg
Join our newsletter to receive a weekly portion of news, articles, and tips about OpenBOM and our community.