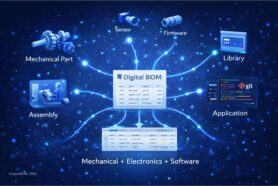
How engineering teams can stop reconstructing product data from CAD applications, PLM databases, BOM spreadsheets, ERP systems, email, and chats
A few years ago, I was in a meeting with an engineering director at a mid-size industrial manufacturer. Her team had just discovered, four days before a product release, that a supplier for a critical subassembly had quietly discontinued the part three months earlier. Nobody had caught it because the engineering BOM lived in one place, the procurement tracking lived in another, and the supplier notification had come in by email — where it sat unread in a shared inbox.
The delay cost them six weeks and a significant redesign. The thing that stuck with me was her description of how it happened: “We just had no idea. Everything looked fine from where we were sitting.”
I’ve heard variations of that story more times than I can count. The titles change — Lead Engineer, Director of Engineering, Head of Product Development, VP of Operations — but the problem is the same.
Last month, at 3DEXPERIENCE WORLD 2026, I talked to many engineers about the new center of gravity for product data. Their SOLIDWORKS environments are built around CAD files, Excel spreadsheets, and different ERP tools created over the past 20+ years.
At some point in the process, the team loses sight of the actual state of the product. Not because they aren’t paying attention, but because the information they need is scattered across a dozen places that don’t talk to each other.
The Hidden Job of Engineering Leadership: Product Data Management for Engineering Teams
When we describe what engineering leaders do, we tend to focus on design, iteration, release management. The glamorous version of the job.
But there’s a less glamorous, arguably more important part: maintaining a reliable representation of what the product actually is.
That means knowing, at any given moment: what makes up the product, which suppliers provide which components, what revisions have happened and why, and how a design change in one area ripples into cost and manufacturability downstream.
If you can’t answer those questions reliably, you can’t really control the product development process. You can only react to it.
And yet most engineering organizations I’ve encountered are essentially reconstructing the state of their own product from scratch every time a decision needs to be made. Someone exports a BOM from CAD. Someone else adds supplier data from a spreadsheet. Procurement pulls cost information from ERP. Engineering tries to reconcile the whole thing before it goes to manufacturing. Inevitably something doesn’t match.
The process works, until it doesn’t. And when it doesn’t, it really doesn’t.
PLM vs Spreadsheets: Why BOM Management Still Breaks in Manufacturing
Most manufacturing companies end up choosing between two imperfect tools for managing product information.
The first is spreadsheets. Engineers love them because they’re fast and flexible — you can spin up a component list or track supplier quotes in an afternoon with no setup required. The problem is that spreadsheets were designed to manage numbers, not relationships. They don’t know that component A is used in assembly B, or that changing a quantity in one tab should update three other tabs. Over time, spreadsheets multiply. You end up with a dozen versions floating around, maintained by different people, diverging in ways nobody fully tracks. Usually teams appoint someone to play a role of a “Chief Excel Officer” – the role I identified a long time ago.
I’ve seen companies where reconciling the various product spreadsheets before a release took a dedicated engineer two full weeks. Every single release.
The second option is traditional PLM. The pitch is compelling: structured workflows, revision control, product hierarchy management, traceability. In practice, many organizations find that large PLM implementations take 6 to 18 months to configure, require training, and still end up requiring spreadsheets exports alongside them because the system is too rigid for the way engineers actually work. I have many stories when users export BOMs from PLM software, edit it and then import back.
Neither option is wrong, exactly. Both are optimized for something real. But neither was designed for the core problem, which isn’t about files or workflows — it’s about knowledge.
The Real Problem: Product Knowledge Gets Lost Between Systems and People
Every engineering decision generates knowledge about the product. Why was this supplier chosen? What tradeoffs were made when the design changed in revision four? What’s the lead time risk if this component goes out of stock?
In most organizations, that knowledge evaporates. Some of it gets captured in files. Some lives in emails. A significant amount lives only in the heads of engineers who worked on the design — and who might leave the company or move to another project.
This is the real cost that doesn’t show up on any spreadsheet: the organizational knowledge about a product that gets lost between decisions. When a new engineer joins the team, or when the product gets handed off to manufacturing, or when a supplier relationship changes, that knowledge has to be painfully reconstructed — often incompletely.
Product Memory is a way of thinking about the solution to this problem. Not just capturing data about a product, but capturing the knowledge: the relationships between components and assemblies, the history of engineering changes and why they happened, the supplier dependencies and risk factors, the cost impacts of design decisions. All of it connected and continuously evolving as the product develops.
The goal is straightforward, even if building it isn’t: your team should always be able to answer the question “what is the actual state of this product?” without having to spend three days reconstructing it from scattered sources.
The Product Loop: How Product Memory Improves Product Data Management in Manufacturing
Product Memory isn’t a database you populate once and maintain. It’s something that has to be continuously captured as engineering work happens — otherwise it immediately starts lagging behind reality.
That requires thinking about four connected activities.
Capturing product data from spreadsheets, CAD, ERP, and supplier systems
Capturing data from the systems that already exist. CAD tools contain assembly structure. ERP systems contain inventory and cost data. Supplier portals contain component specs. The goal isn’t to make engineers enter this information again — it’s to pull it from the sources where it already exists, automatically, so it stays current.
Engineering change management as part of product knowledge
Managing design changes as part of the product record. Products change constantly. The value of tracking those changes isn’t just audit compliance — it’s that each change contains context. Why did this revision happen? What problem was it solving? What were the alternatives? When that context is part of the product knowledge, it becomes genuinely useful for future decisions.
Maintaining connected product structures across teams (DBOM, EBOM, MBOM, SBOM)
Maintaining connected views of the product structure. Engineering teams work with an Engineering Bill of Materials (EBOM) that reflects the design. Manufacturing teams rely on a Manufacturing BOM (MBOM) that reflects how the product is actually assembled.
These can’t be separate documents that drift apart — they need to be connected views of the same underlying product model, so a change in engineering propagates appropriately downstream.
Synchronizing product data downstream and across the digital thread in manufacturing
Letting product knowledge flow into downstream systems. Engineering decisions affect procurement, manufacturing planning, inventory. A connected product model should make it easier — not harder — for that information to reach the people and systems that need it, rather than being manually re-entered at every handoff.
Together, these activities create a loop where product knowledge accumulates and improves over time rather than getting lost between phases.
What Happens When Engineering Teams Have Reliable Product Data
The most immediate effect teams notice is visibility into product completeness. When the product structure is actually connected and current, incomplete assemblies and missing components become obvious before they become problems. You stop finding out that something is wrong at the moment you can least afford it.
The second effect is better cost and supply chain insight. Because components and suppliers are connected to the product model, engineering teams can see how a design decision affects cost and supplier risk before the decision is locked in. This sounds obvious. It’s surprisingly rare in practice.
The third effect is harder to quantify but arguably the most important: teams stop spending time managing data and start spending time making decisions. The two-week spreadsheet reconciliation cycle goes away. The frantic pre-release verification ritual gets shorter. Engineers can actually focus on engineering.
There’s also a forward-looking dimension worth considering. As AI tools begin to enter engineering workflows, the quality and structure of product data will determine how useful those tools can actually be. An AI agent that can analyze your product structure, flag potential BOM errors, model the cost impact of a component change, or surface supplier risk — that’s genuinely valuable. But it requires structured, connected product knowledge to operate on. Fragmented spreadsheets and disconnected files don’t give AI much to work with. Product Memory does.
Product Memory and the Digital Thread in Manufacturing
Software development went through a nearly identical transformation between roughly 2000 and 2015. Before version control became standard practice, software teams managed code in local folders, coordinated releases by emailing zip files, and regularly had no reliable way to answer “what version is actually running in production?”
It sounds absurd now. But it wasn’t that long ago, and the transition wasn’t obvious while it was happening. Developers who’d always worked that way had to be convinced that shared repositories and continuous integration were worth the adoption cost.
Manufacturing is in a similar moment. The tools exist to manage product knowledge in a connected, structured way. The cost of fragmented product information is high enough — and increasingly visible enough — that organizations are starting to look seriously at the problem.
The parallel isn’t perfect. Physical products are more complex than code in some ways, and the systems involved are more heterogeneous. But the underlying shift is the same: from managing isolated artifacts to managing connected knowledge.
The Cost of Bad Product Data Management in Manufacturing
I’ll end with what I think is the most useful framing for engineering leaders thinking about this problem.
The question isn’t “should we invest in better product data management?” Most engineering leaders already know the answer to that.
The question is: what does it actually cost us, right now, to not have a reliable picture of our product? Count the hours spent reconciling spreadsheets before releases. Count the delays caused by missing component information. Count the engineering rework triggered by supply chain surprises that could have been caught earlier. Count what it costs when institutional knowledge walks out the door with a departing engineer.
For most manufacturing organizations, that number is significant. The challenge is that it’s distributed across dozens of small inefficiencies and near-misses rather than showing up as a single line item.
Product Memory is a way of attacking that cost systematically — not as a one-time tool deployment, but as a shift in how the organization thinks about and manages the knowledge embedded in its products.
The companies building the most complex products in the world are the ones figuring this out. The ones that don’t will find that complexity increasingly difficult to manage — not because they lack talent or resources, but because they’re still trying to reconstruct the truth about their own products every time they need to make a decision.
Want to discuss Product Memory?
Contact us and we would be happy to jump on a call to talk about how it can help your team or company.
Best, Oleg
Join our newsletter to receive a weekly portion of news, articles, and tips about OpenBOM and our community.