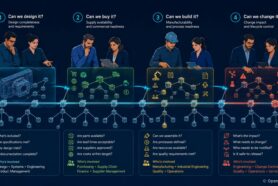
Technology is moving forward and pushing our demands to new highs. Just a decade ago, no one was asking a toothbrush to give them recommendations on how to change the pattern they use it, your grill was not adjusting the product based on the recipe downloaded from the internet and cars were not self-adjusting to road conditions and communicating with each other. I can bring more examples, but the funny part is that you live surrounded by these new objects – connected cars, smart homes, self-driving robots delivering packages, and many others. Let’s take a typical car. Each car today consists of dozens of thousands of components – mechanical, electronic, software produced and delivered by thousands of suppliers. It is insanely complex and configurable.
Modern Manufacturing Process and Challenges
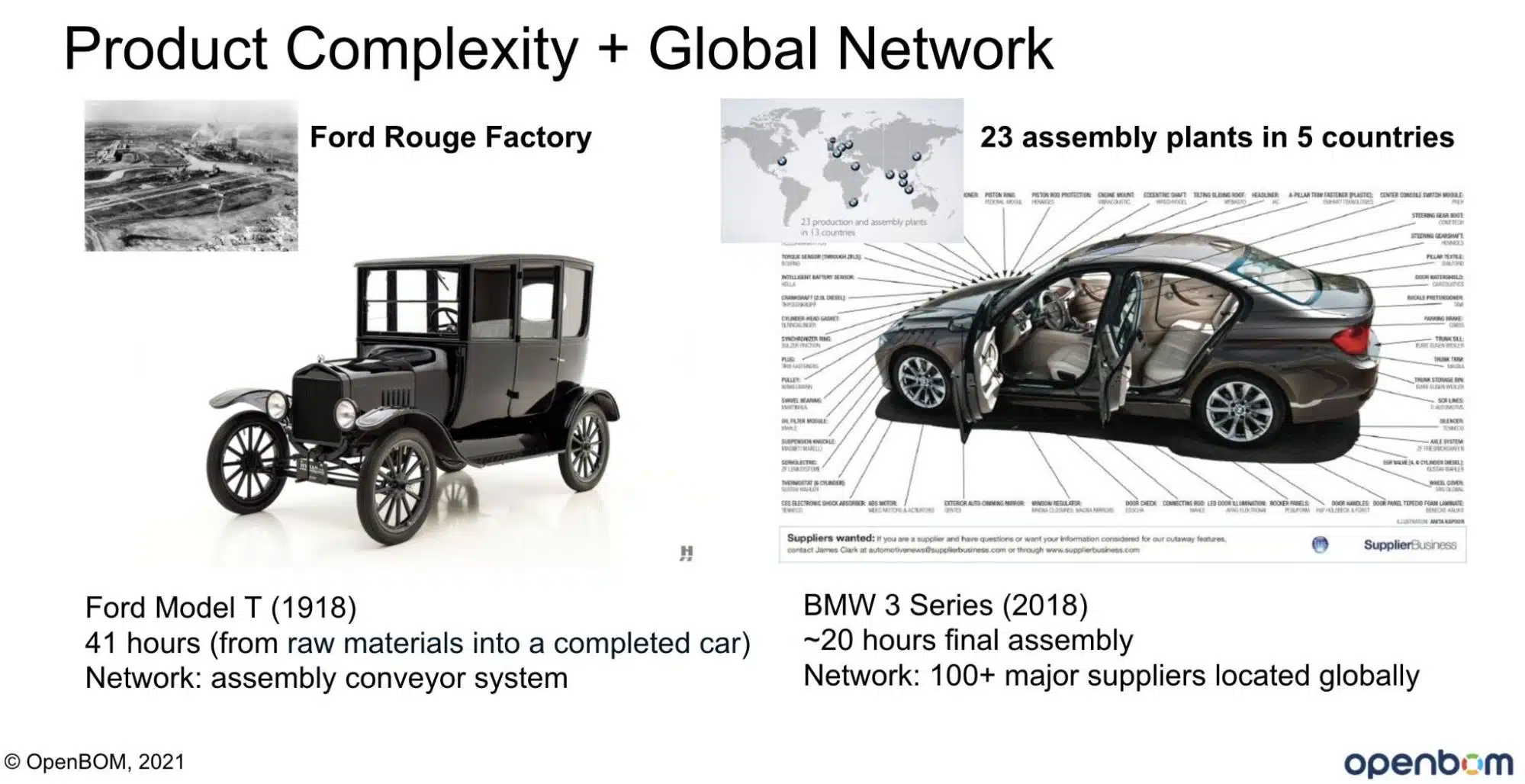
Check the following picture to give you an idea of the complex differences between the Ford Model-T and modern BMW cars.
Each component in a modern product has its own product development process and a lifecycle. It can become obsolete and suddenly become unavailable. Each component is going through a lengthy development process, including releases, and changes. Each of these components and units has its own compatibility rules driven by configuration, local market, regulations, and many others.
The decision process in each manufacturing company is insanely complex, but unfortunately, the data management systems that are used to handle all these levels of data complexity are insanely outdated. The majority of PLM systems in production were developed 20+ years ago and are using relational databases as the only way to store and manage the data. The data is siloed between multiple systems and tons of Excels and legacy databases. As a result, companies have a hard time answering some critical questions. I’m not even talking about the need to manage data-driven decisions in real-time.
In my earlier article OpenBOM Graph Centered Applications, I shared an example of the questions manufacturing companies are facing that are hard to get answers to using traditional data management methods and applications.
- What will be the cost impact if component A cost increases?
- What will be the impact on product delivery if supplier B is shut down?
- Do we have parts with a single-source supplier for the product?
- What if component A will not be allowed in the US from 2020?
- How to validate compliance with the product for a new market?
Traditional PLM Data Management Architectures
Existing PLM systems provide very little help to solve the problems I mentioned above. The majority of them are limited to a traditional data management system (Relational Database) and run on premise. Even, vendors are moving to SaaS (or cloud), it basically means hosting of existing PLM systems using virtualization architectures in public IaaS platforms or using special private hosting providers. It might solve IT management problems, but doesn’t change the system and their capabilities.
The siloed data, no access to multiple sources and information, and most importantly limited technological capabilities don’t give many answers to enterprises looking on how to improve their data management and analytics capabilities.
SaaS and New Data Management Architectures for PLM
How to solve the problem and how new technologies and SaaS data management architecture can help? There are 3 fundamental elements of the new system architecture that traditional PLM systems cannot do.
Modern data management is moving from a single database architecture to polyglot persistence. The terminology is funny, but the logic is simple. Like in programming (polyglot programming), software engineers are using different programming languages to write applications for better performance, user experience, and logic. The set of databases are becoming a toolkit to provide the needed way to manage the data.
Traditional databases are enhanced or replaced by modern Document Databases, Graph Databases, Search Indexes, and other data management tools that combined with microservice architecture provide much more flexibility, scale, and intelligence to manage information.
At OpenBOM, the core data architecture is using a combination of databases (including Graph Database) to manage semantic relationships and provide a source of data analytics. OpenBOM manages the entire data relationships set using Graph Database, which provides a much better fit and source of intelligence for product structure, dependencies, and relationships.
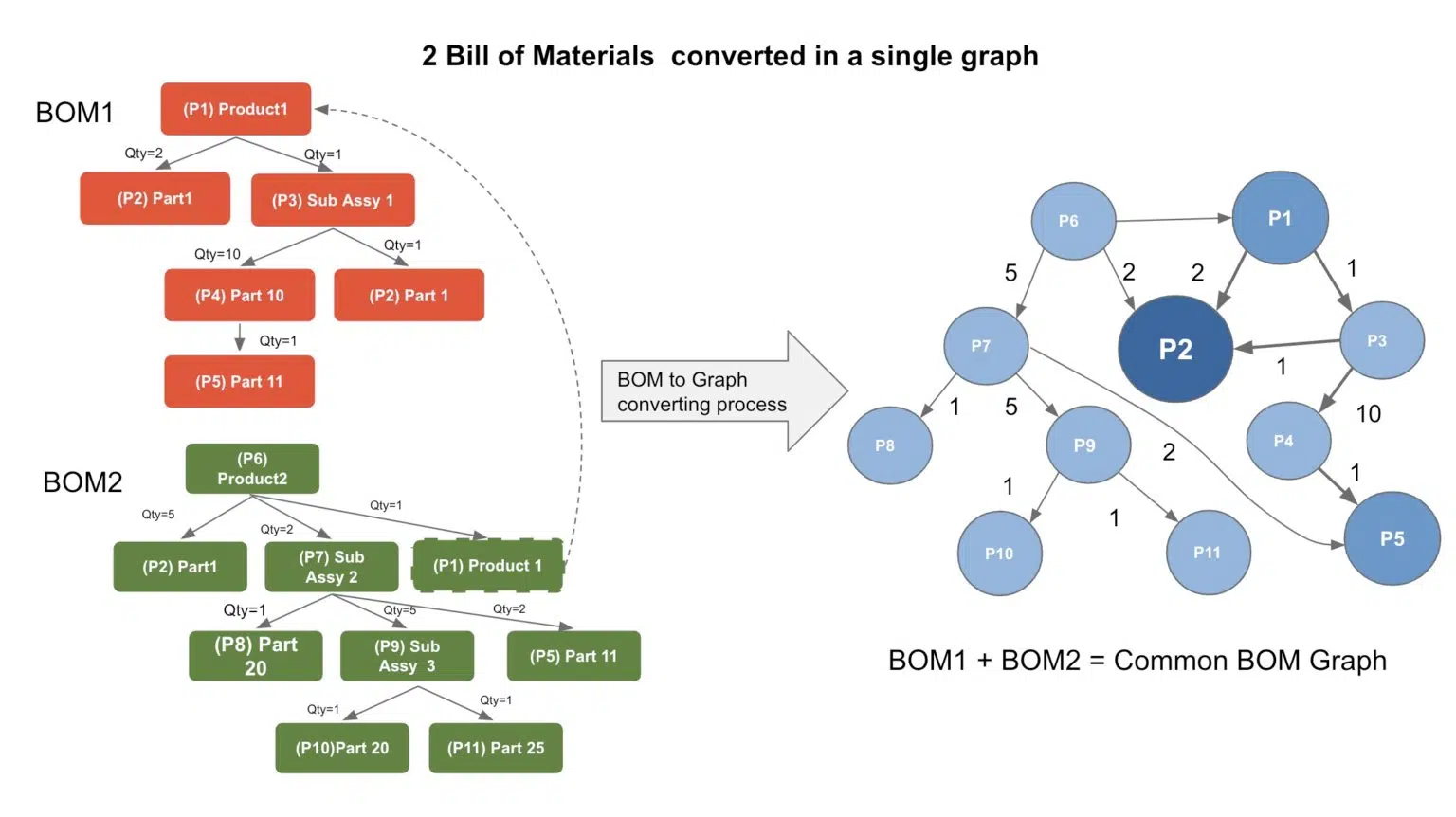
OpenBOM’s flexible data model allows it to absorb the data from multiple sources and create a combined data set capable of managing the complexity of relationships.
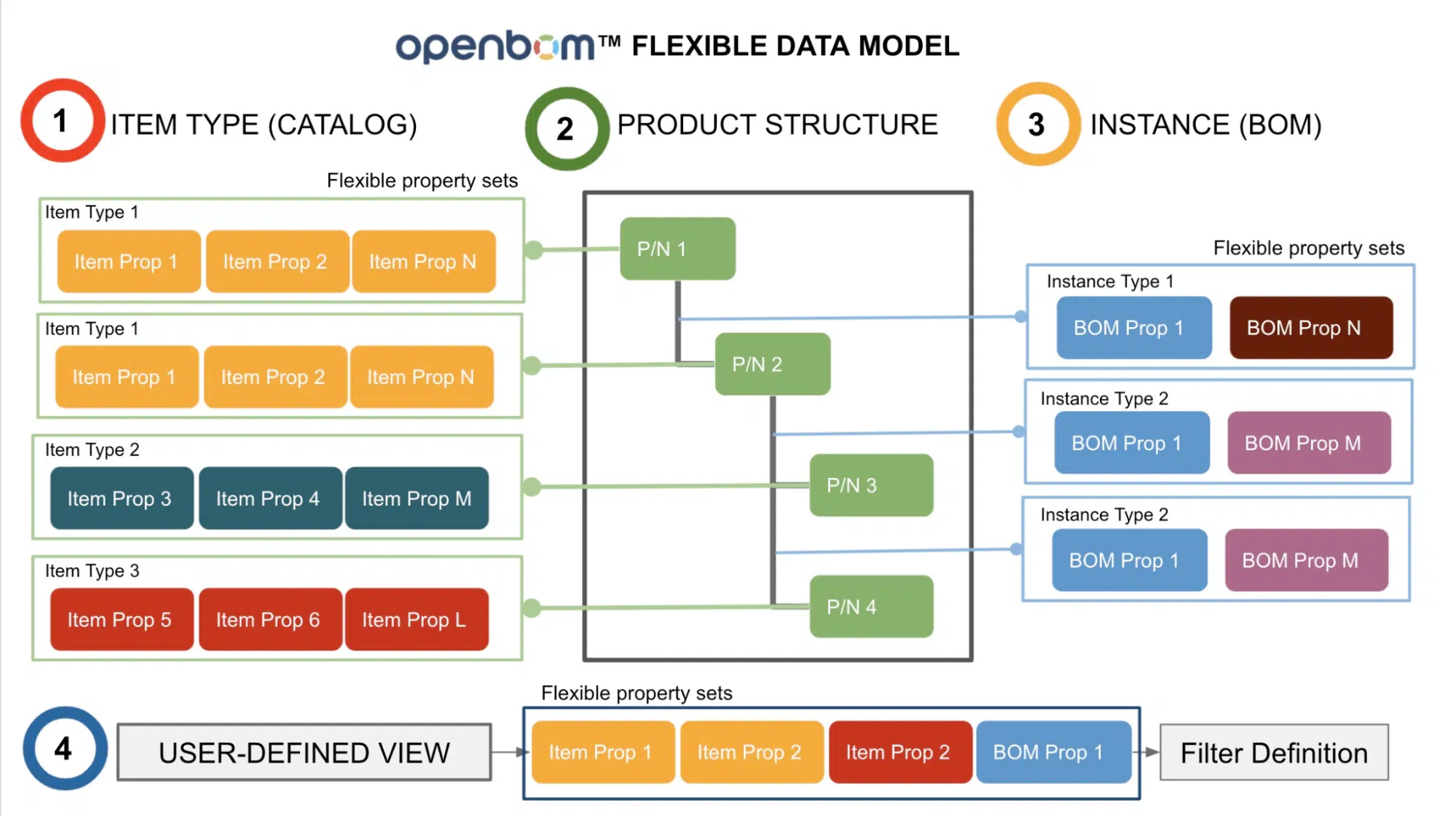
Multi-tenant architecture of OpenBOM allows gleaning intelligence from the data silos of large data sets. Imaging the enterprise OEM loading design data of multiple brands and products in OpenBOM and getting various ways of intelligent product data discovery mechanism and tools provided by search platforms and graph databases.
Global BOM Graph
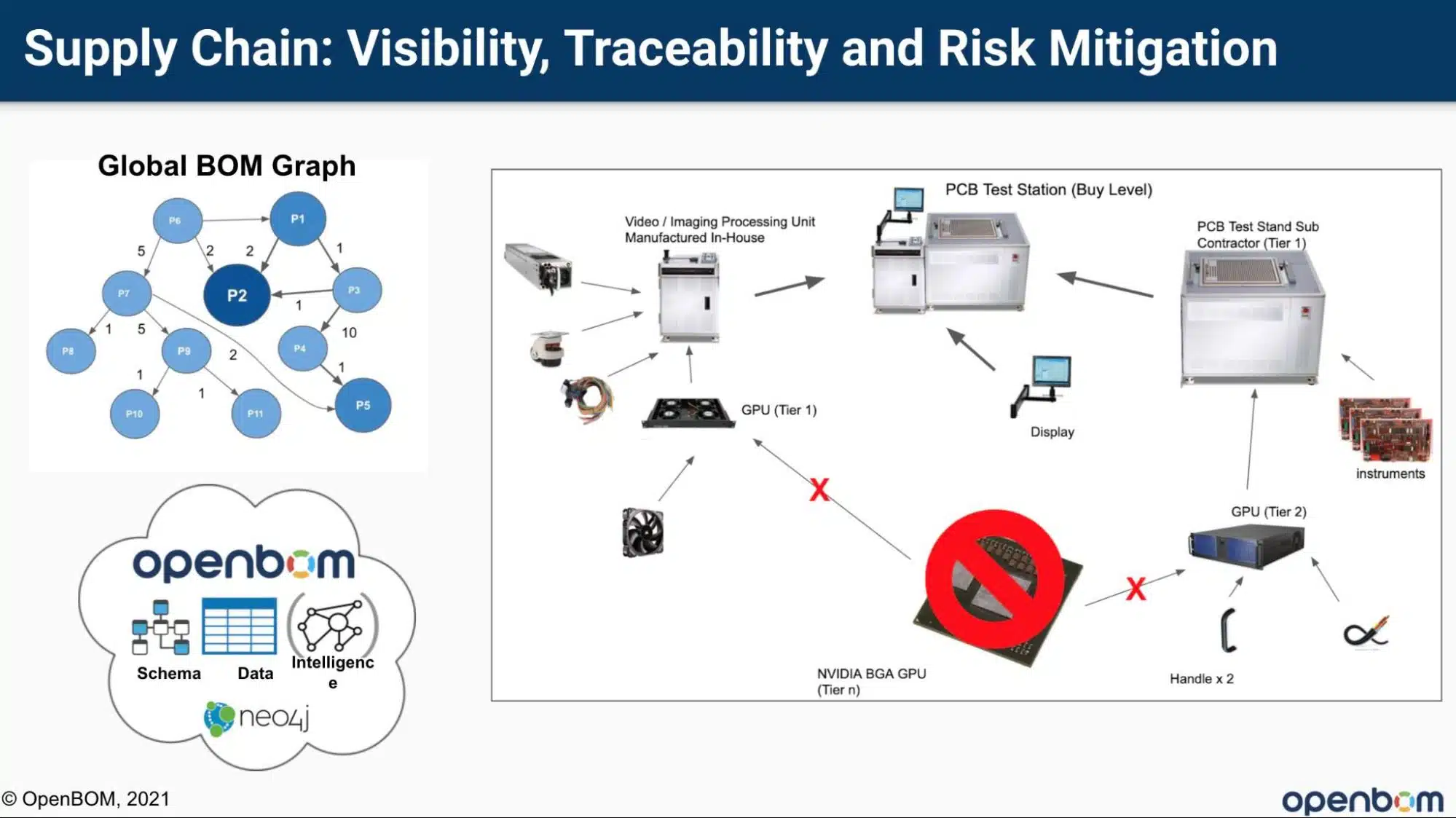
The core part of OpenBOM intelligence is a Global BOM Graph, that can be built using acquired data from multiple sources of information- design, CAD systems, enterprise systems – CRM, ERP, PLM, etc. The foundation of the global BOM graph is managed OpenBOM relationships service powered by Graph Database and connecting with other pieces of information.Conclusion
Manufacturing companies must become data-driven. This is a survival recipe for the 21st century. To do so is impossible when using old systems developed 20-30 years ago not capable of managing the complexity and semantics of modern products and their organizational relations.
OpenBOM is a new type of data management system providing a scalable platform and network layered to manage relationships between manufacturers, suppliers, contractors and providing an intelligent data layer to fuel data-driven decision processes.
Interested in learning more about how OpenBOM can help you? Then check out our website for your free 14-day trial and contact us. We would be happy to help.
Best, Oleg
Join our newsletter to receive a weekly portion of news, articles, and tips about OpenBOM and our community.