
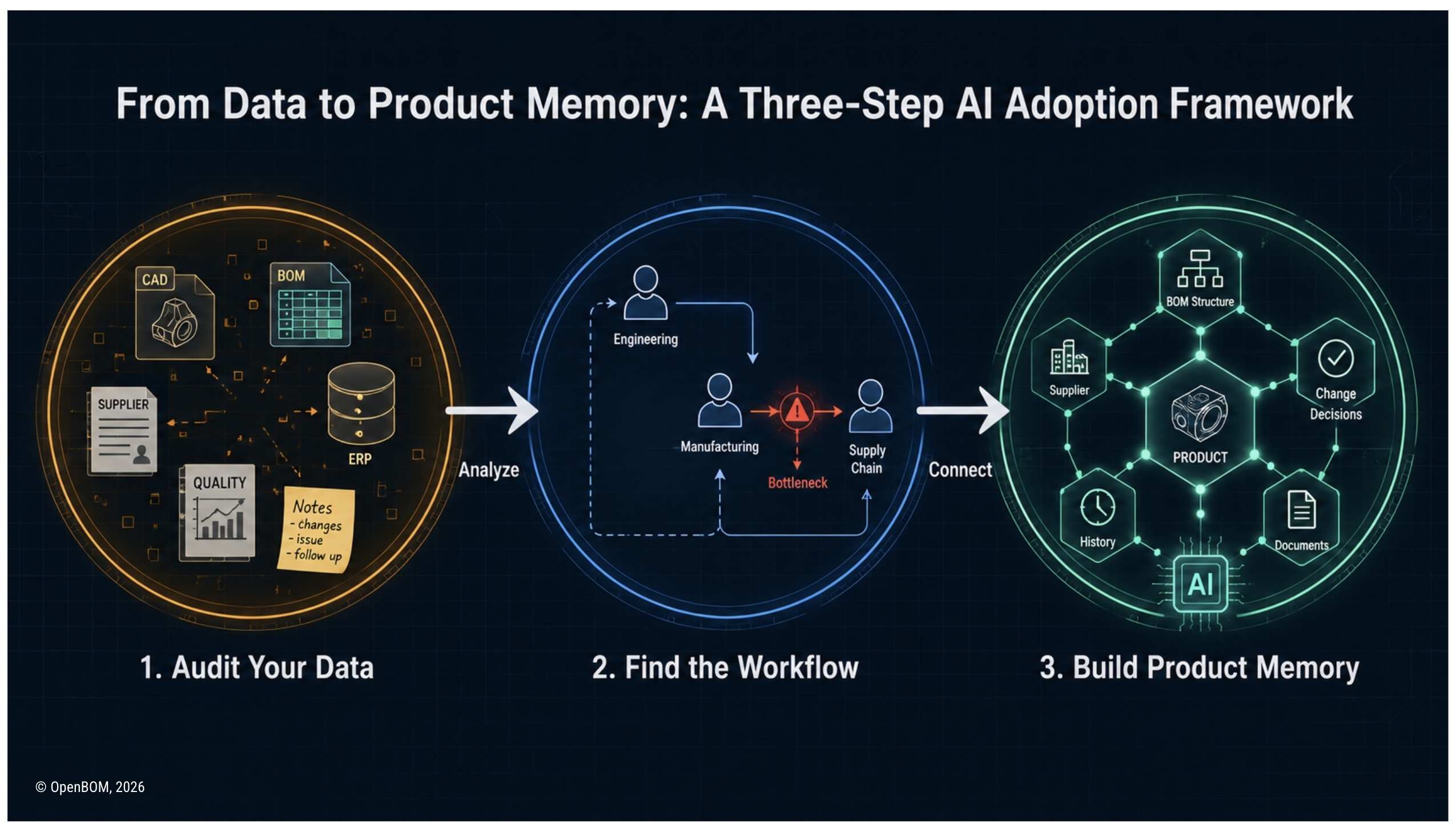
Companies struggle to get real business value from AI in engineering and manufacturing not because the technology is weak, but because product data is fragmented and disconnected. This article explains how to close that context gap using a three-step approach: audit your data, identify the right workflow, and build product context before applying AI.
Last week I attended SharePLM Summit, and I came back with a clearer sense of something I had been thinking about for a while. I wrote a longer reflection on the broader industry conversation over on Beyond PLM — if you have not read it, I would recommend starting there. But there is a more practical side to this question that I want to explore here on the OpenBOM blog, because it connects directly to what we see when working with engineering and manufacturing teams every day.
Everyone is talking about AI. That part is no longer interesting. What is interesting is why AI adoption in product development is so much harder than AI adoption in personal productivity. The same person who uses ChatGPT fluently at home struggles to get meaningful results from an AI tool inside their engineering workflow. The model did not get worse. Something else changed.
That something is context. And context starts with data.
What Is the Context Gap and Why Does It Block AI Adoption in Engineering
I have started calling this the context gap. It is the distance between what a general-purpose AI model knows and what it needs to know to help with a specific enterprise task.
An LLM can explain what a BOM is. It can describe the steps of an engineering change process. It can generate a generic supplier qualification checklist. But when the question becomes “can we release this BOM to manufacturing,” the answer is no longer general. It depends on product structure, item data, revision history, supplier status, cost information, open change orders, manufacturing constraints, and dozens of previous decisions that shaped where the product is today.
Without that context, the model produces generic output. It is not wrong in a technical sense. It is just not useful in a business sense. And that distinction is the one that frustrates engineering teams most.
The context gap is not a model quality problem. Switching to a better LLM will not close it. The gap exists because enterprise product data is fragmented across CAD files, BOMs, PLM databases, ERP records, supplier tables, quality reports, spreadsheets, emails, and people’s memories. Having all of that data somewhere in your organization is not the same as having it organized into context an AI can use.
Step 1: Audit Your Product Data Before Choosing Any AI Tool
This is where most companies get the sequence wrong. They identify a problem first, then go looking for the data to support it. In my experience, the better approach is the reverse. Start by understanding your data landscape honestly, and the real problems will surface from that analysis.
Most engineering and manufacturing companies have more product data than they realize, and less organized context than they think. Before asking AI to help with anything, a company needs to answer a set of basic but hard questions about its own information.
Where does product knowledge actually live? In most companies the answer is everywhere: CAD files on shared drives or PDM systems, BOMs in spreadsheets or PLM, item records in ERP, supplier information scattered across emails and procurement systems, quality data in separate tools, change history in yet another system, and critical decisions living only in experienced people’s heads.
Which data is structured and which is not? A BOM in a PLM system is structured. A design rationale buried in an email thread is not. Both are product knowledge. Only one is accessible to AI without significant effort.
Which data is trusted? This is often the most uncomfortable question. In many companies the same information exists in multiple places and nobody is entirely sure which version is current. Engineers know which spreadsheet is real. They know which ERP record lags behind engineering reality. They know which supplier data is stale. AI does not know any of this unless the organization makes it explicit.
Which knowledge exists only in people’s heads? Every experienced engineer carries product context that was never captured formally. Why a particular supplier was chosen. Why a design decision was made under schedule pressure. Why a specific component has a known limitation that never made it into any document. This is the most fragile category of product knowledge, and it is the first to disappear when people leave or change roles.
This data audit does not need to be a formal project. It does not need to produce a perfect data model before anything else can happen. The goal is visibility: an honest map of where product knowledge lives, how reliable it is, and where the most significant gaps are. That map becomes the foundation for everything that follows.
Step 2: Identify Which Engineering Workflows Suffer Most From Missing Product Context
Once you have a clear picture of your data landscape, the painful workflows become much easier to identify. You are no longer guessing at problems. You are reading them directly from the data map.
Look for the places where people spend time compensating for missing or disconnected context. Where do engineers search across multiple systems to answer a question that should have a single clear answer? Where does a change process slow down because nobody can quickly understand what changed, why it changed, and what it will affect downstream? Where does manufacturing receive incomplete information from engineering and spend time reconstructing context before they can act? Where do new team members take months to understand product history that should be accessible in days?
These workflows share a common characteristic: the hard part is not the task itself. The hard part is reconstructing the context needed to perform the task. A BOM review is not conceptually difficult. What makes it time-consuming is hunting across systems for supplier status, checking whether a component was superseded in a recent change order, validating cost data that may or may not be current, and confirming that manufacturing requirements have been updated to reflect the latest engineering revision.
This is where AI can help. But only once the data foundation is clear enough to support it.
The workflow analysis step asks a focused question: given what we now know about our data landscape, where does fragmented or missing context create the most friction for real people doing real work? The answer to that question is your AI starting point.
Same LLM, Completely Different Results: Why Product Context Is Everything
The most useful way I have found to explain why data comes first is through a simple comparison.
Imagine asking an AI model to review a BOM and tell you whether it is ready for manufacturing release. If you upload a spreadsheet in isolation, the model can find missing values, flag duplicate rows, and suggest that manufacturer part numbers are absent. That is genuinely useful. But it cannot tell you whether the selected supplier has been approved for this commodity. It cannot know whether this item already exists in ERP. It cannot know whether a substitute component was approved three weeks ago in a separate change order. It cannot know whether manufacturing rejected this part in a previous build.
The model is not weak. It is blind. It cannot see what was never given to it.
Now imagine the same AI model connected to an organized product data layer. It knows the BOM structure, item records, revision history, supplier status, open and closed change orders, and what manufacturing requires before a release can proceed. Now the same model can say: this BOM is not ready for release because two purchased parts are missing approved suppliers, one component was superseded in a previous change order but still appears here, and the manufacturing view has not been updated since the last engineering revision.
That is not a generic AI response. That is a business answer. And the difference between these two outcomes is not the model. It is the data and context organized around the model.
Step 3: Build Product Memory for One Workflow Before Scaling AI
Once the data landscape is mapped and the most painful workflow is identified, the third step is to build enough organized context to support AI in that one workflow. Not everything at once. One product line, one BOM process, one change workflow, one supplier handoff.
This is where the concept of Product Memory becomes important. AI cannot operate on disconnected fragments. It needs organized context: product structures, relationships, decisions, changes, ownership, history, and the dependencies between them. Product Memory is the layer that connects these elements so that AI can work with product knowledge in a meaningful way rather than responding to isolated data points.
This approach is deliberately iterative. Build context around one real problem. Apply AI to improve one specific workflow. Measure the result. Then expand. This is very different from the old enterprise software mindset of defining a complete data model, implementing a large system, migrating everything, and only then expecting value.
At OpenBOM, this is the direction we are building toward: a product data layer where CAD files, BOMs, item records, supplier information, and change history are connected and accessible, giving AI the context it needs to participate in real engineering and manufacturing work rather than just answer general questions about it.
Why AI in Manufacturing Needs Governance, Workflow Controls, and Human Review
Organized data and context are necessary but not sufficient. AI in enterprise workflows also needs a controlled environment that allows it to operate safely and usefully inside real business processes.
That environment includes access to the right data, permissions and security boundaries, workflow state awareness, business rules, traceability, and human review at the right moments. Without these controls, AI is a conversational layer sitting next to the actual work. With them, AI becomes part of the workflow.
This matters especially in product development because engineers and manufacturing teams work with high-stakes information. They will not trust an AI recommendation unless they can see where it came from, what data it looked at, and who approved the underlying records. Trust is built through transparency and governance, not through capability demonstrations alone.
How to Start Your AI Adoption Project in Engineering: A Three-Step Summary
The conversation at SharePLM Summit confirmed something I already believed: companies are ready to move past AI curiosity. They are not asking whether AI is powerful. They are asking how to apply it to real work without creating new risks or new confusion.
The answer is more straightforward than most AI strategy documents suggest. Audit your product data first — map where knowledge lives, how reliable it is, and where the gaps are. Then identify which engineering workflows suffer most from that fragmented context. Then pick one of those workflows and build enough organized product context to support AI in that specific task.
That sequence — data first, workflow second, AI use case third — is the practical path from AI experimentation to measurable business value in engineering and manufacturing.
If you are working through this question and want to talk through your specific data and workflow situation, reach out. This is exactly the conversation we are having with engineering and manufacturing teams right now.
Tell us what you think? Do you have a project to start you AI adoption?
Meantime REGISTER FOR FREE to check how OpenBOM can help.
Contact us to discuss.
Join our newsletter to receive a weekly portion of news, articles, and tips about OpenBOM and our community.








