In modern manufacturing, data is the new infrastructure. From design to procurement, from production planning to supplier collaboration, every process depends on the ability to organize, access, and share accurate information in real-time. Yet, many companies are still constrained by outdated PLM and PDM systems that were never designed for today’s connected, cloud-native world.
Over the past couple of weeks, I’ve written several articles about OpenBOM data modeling. Today’s post is the final one in this series, where I’ll focus on OpenBOM’s Data Management Architecture and how it differs from traditional PLM and SaaS tools.
Related Articles (OpenBOM Data Model 2025 Update Series):
- OpenBOM Data Model 2025 Update: A High-Level Overview
- OpenBOM Core Data Model: Objects, Properties, and Links
- Reference-Instance Product Structure and xBOM: A Modern Data Architecture for Product Models
- OpenBOM Design Projects and PDM Service Data Model
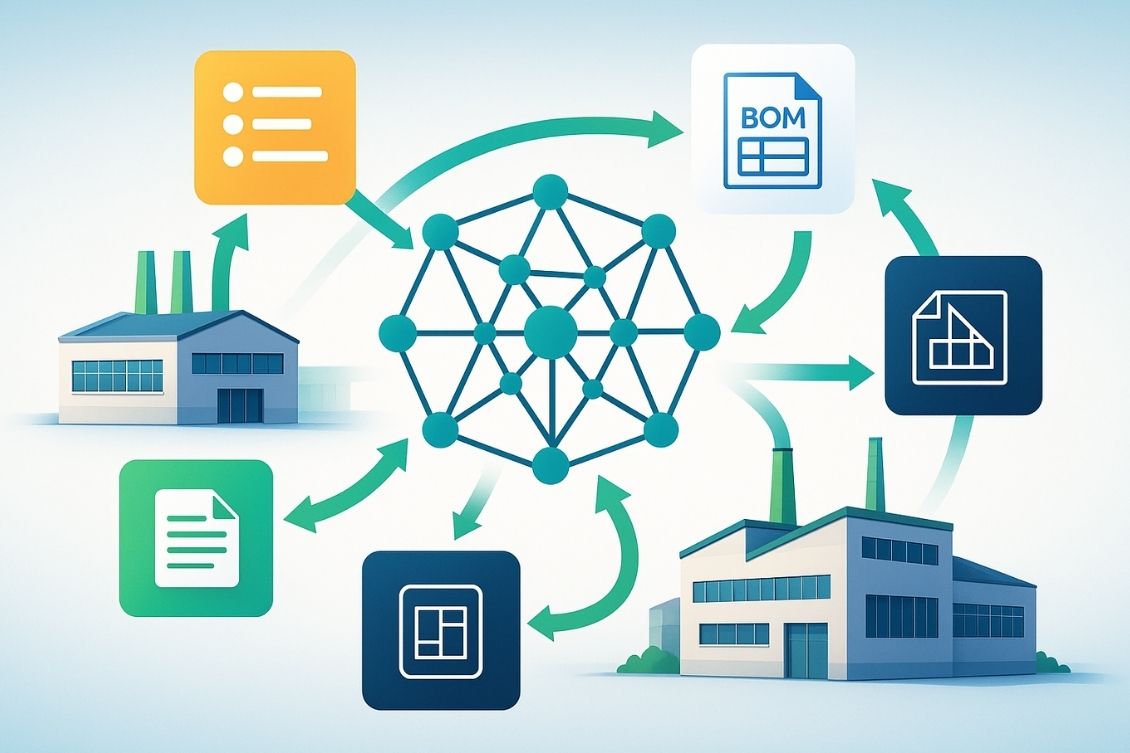
At OpenBOM, we take a different approach. Our graph-based, microservices-driven, polyglot-persistent data architecture is built for the realities of global engineering and manufacturing. It does more than just store files and properties—it creates a living, connected product knowledge graph that powers collaboration, decision-making, and innovation at scale.
Why does this matter? Because data architecture is not just technical—it is strategic. The way information is structured and managed changes every aspect of PLM: user experience, scalability, economics, and even the types of problems you can solve.
Why OpenBOM Data Architecture Is Different
Traditional PLM platforms were built as monolithic applications sitting on top of a single SQL database. While this approach worked for many years of PDM/PLM, it has reached its limits from both technical and economical perspectives – rigid schemas, poor scalability, high customization costs, and difficulty supporting global collaboration.
OpenBOM is different. We use a multi-tenant, polyglot-persistent, microservice architecture designed from the ground up for the cloud. This means:
- Multi-tenant: multiple companies can run on the same infrastructure, securely and efficiently.
- Polyglot persistence: we use the right database for the right job—graph databases for relationships, document stores for flexible models, cloud infrastructure for structured transactions.
- Microservices: lightweight, independent services connected through APIs, ensuring agility, scalability, and resilience.
The result? A system that is scalable, flexible, high-performing, and cost-efficient – all together, the qualities that monolithic PLM systems cannot match.
Right Database Technology for the Right Job
One of the biggest differentiators of OpenBOM is our polyglot persistence model. Instead of forcing all data into a single relational database, we use multiple database technologies, each optimized for a specific type of task:
- Flexible NoSQL models: for catalogs, BOM properties, and rapidly evolving schemas.
- Graph databases: for managing connections between items, structures, and digital threads.
- Search-optimized engines: for fast, specialized queries and indexing.
This approach enables capabilities that traditional SQL-driven systems struggle with:
- Collaborative workspace data management: real-time editing of BOMs and other data objects across teams and suppliers, automatic history tracking, no locking.
- Graph queries: instantly answering questions like “where is this part used?” or “which items are most connected?”
- Graph analytics: running algorithms to detect “mostly connected” components, patterns in product structures, or risks in supply chains.
Contrast this with legacy SQL systems, which are inflexible, perform poorly under complex queries, and become prohibitively expensive to scale globally.
High-Level Data Management Tech Stack
To understand how this works in practice, let’s look at OpenBOM’s five-level stack:
- Database layer – polyglot persistence (MongoDB, Neo4j, Elastic, and few other DBs).
- Microservices layer – modular, containerized services running in the cloud.
- Product Knowledge Graph – unified representation of data objects for items, catalogs, BOMs, orders, POs, Design Items, Custom Objects, relationships, and digital threads.
- Application services & integrations – APIs, connectors, and integrations with CAD, ERP, and other systems.
- User services & applications – SaaS apps, dashboards, collaborative editors, and analytics tools.
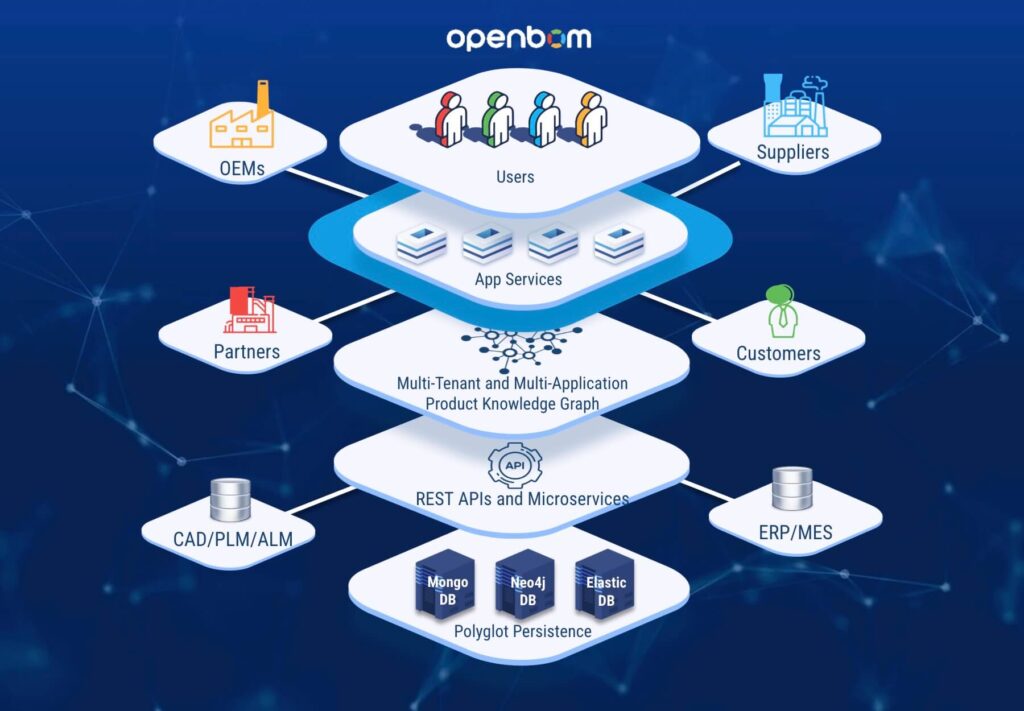
Key characteristics of this stack:
- Containers and microservices for agility.
- Connected and federated, not monolithic.
- Multi-tenant, multi-company data model.
- Patented real-time collaboration and simultaneous editing.
- Role-based instant sharing and permissions.
- Graph data science and AI/LLM integration support.
- DBaaS for MongoDB, Neo4j, Elastic on AWS ECS with DevOps automation.
This stack gives OpenBOM the foundation to scale globally, adapt quickly, and enable advanced use cases like product memory and AI-driven workflows.
Logical Data Architecture
The logical structure of OpenBOM’s data model is just as important as the technology underneath. It organizes information into layers that are both standardized and extensible:
- Data Objects – the foundation, including Core Data Objects and Data Elements such as views and properties.
- System Objects – built-in models: catalogs, items, BOMs, design projects, orders, purchase orders.
- Custom Data Objects & Object References – extend the model with domain-specific objects or relationships.
- Customer Data Schemas – tailor-made configurations for each company, balancing flexibility with consistency.
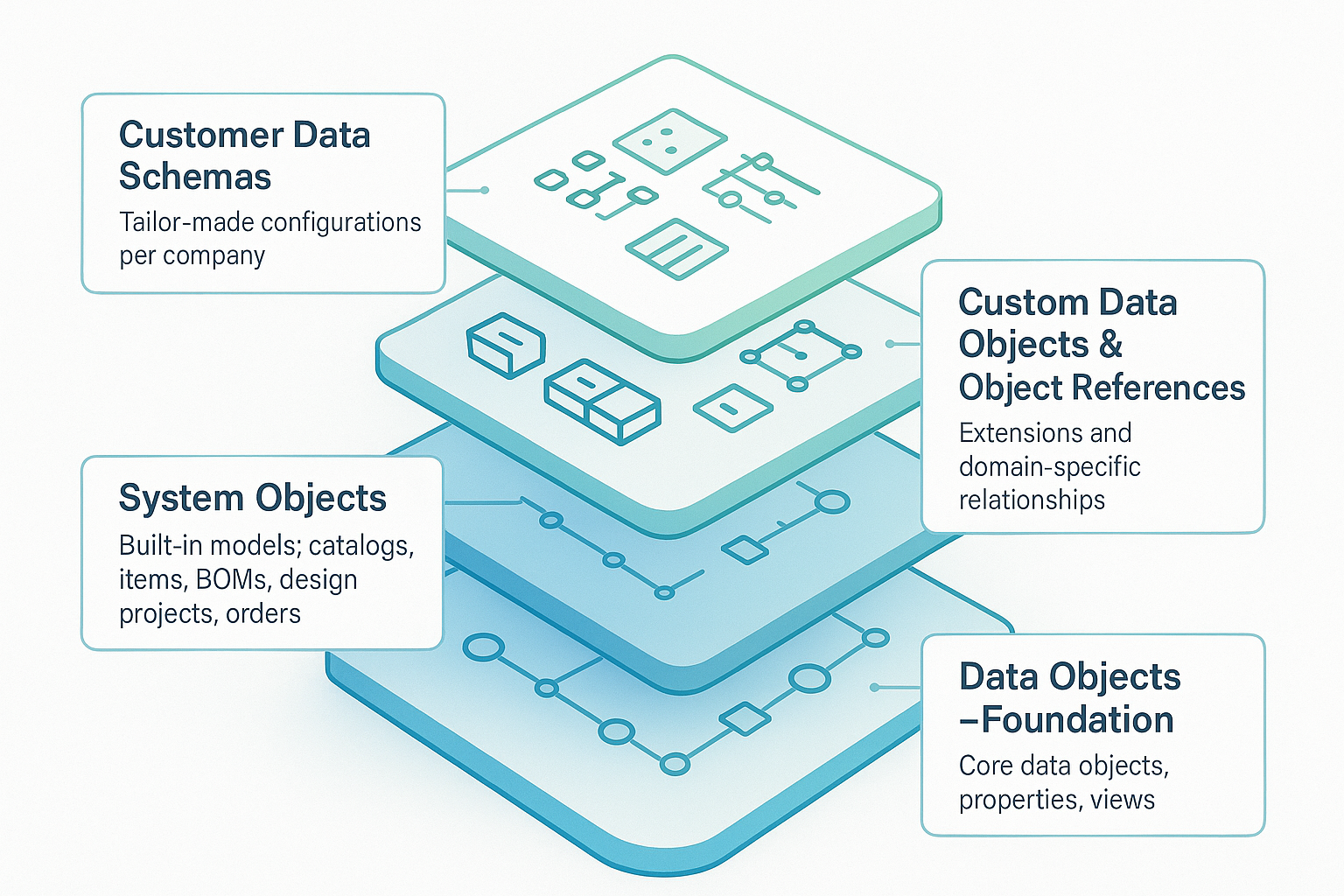
This design ensures that OpenBOM works out-of-the-box, but can also adapt to unique business processes without breaking the system.
Multi-Tenancy and Customization
A true cloud-native platform must support multi-tenancy. At OpenBOM, this means every customer shares the same infrastructure while retaining secure, isolated data environments.
But unlike legacy single-tenant systems, each tenant can fully customize their data model—properties, object types, schemas—without losing compatibility with the overall system.
This balance between shared infrastructure and individual customization is what makes OpenBOM scalable, cost-efficient, and adaptable to companies of all sizes.
Data Sharing Between Tenants
Data silos are one of the biggest barriers in manufacturing collaboration. OpenBOM solves this with secure, role-based sharing, similar to how Google Docs works.
- You can share BOMs, catalogs, or design projects instantly across teams, suppliers, or partners.
- Permissions control who can view, edit, or comment.
- All edits happen in real time, with full traceability and audit logs.
This ability to collaborate across tenants creates the foundation for a digital thread that spans the extended enterprise—connecting engineering, procurement, and manufacturing networks seamlessly.
Conclusion
Data architecture is not just a back-end choice—it defines how companies work, innovate, and compete. OpenBOM’s graph-based, multi-tenant, polyglot-persistent microservice architecture provides the agility, scalability, and intelligence that modern manufacturing demands.
By combining flexible data objects, a product knowledge graph, and real-time collaboration, OpenBOM is building the digital-thread backbone for the future.
Looking forward, this architecture is what enables AI-driven insights, product memory, and agent-based workflows—capabilities that will define the next era of PLM and manufacturing innovation.
REGISTER FOR FREE to check OpenBOM Data Modeling and experiment with how it works.
Best, Oleg
Join our newsletter to receive a weekly portion of news, articles, and tips about OpenBOM and our community.